Reading-notes
Machine learning
Machine learning is the practice of teaching computers how to learn patterns from data, often for making decisions or predictions.
is not about algorithms.
Machine learning is a comprehensive approach to solving problems and individual algorithms are only one piece of the puzzle. The rest of the puzzle is how you apply them the right way.
Key Terminology
Model - a set of patterns learned from data.
Algorithm - a specific ML process used to train a model.
Training data - the dataset from which the algorithm learns the model.
Test data - a new dataset for reliably evaluating model performance.
Features - Variables (columns) in the dataset used to train the model.
Target variable - A specific variable you’re trying to predict.
Observations - Data points (rows) in the dataset.
Machine Learning Tasks
you should first pick the right machine learning task for the job.
- A tas1- k is a specific objective for your algorithms.
- Algorithms can be swapped in and out, as long as you pick the right task.
- In fact, you should always try multiple algorithms because you most likely won’t know which one will perform best for your dataset.
categories of tasks:
1- Supervised Learning
tasks for “labeled” data (i.e. you have a target variable).
Each observation must be labeled with a “correct answer.”
Only then can you build a predictive model because you must tell the algorithm what’s “correct” while training it (hence, “supervising” it).
Regression is the task for modeling continuous target variables.
Classification is the task for modeling categorical (a.k.a. “class”) target variables.

2- Unsupervised Learning
tasks for “unlabeled” data (i.e. you do not have a target variable).
Unlabeled data has no predetermined “correct answer.”
You’ll allow the algorithm to directly learn patterns from the data (without “supervision”).
Clustering is the most common unsupervised learning task, and it’s for finding groups within your data.

The 3 Elements of Great Machine Learning
1- human guidance
2- clean, relevant data
3- avoid overfitting
The Blueprint
There are 5 core steps:
1-Exploratory Analysis
First, “get to know” the data. This step should be quick, efficient, and decisive.
2-Data Cleaning
Then, clean your data to avoid many common pitfalls. Better data beats fancier algorithms.
3-Feature Engineering
Next, help your algorithms “focus” on what’s important by creating new features.
4-Algorithm Selection
Choose the best, most appropriate algorithms without wasting your time.
5-Model Training
Finally, train your models. This step is pretty formulaic once you’ve done the first 4.
Exploratory Analysis
The purpose of exploratory analysis is to “get to know” the dataset.
exploratory analysis for machine learning should be quick, efficient, and decisive… not long and drawn out!
Plot Numerical Distributions
-
Distributions that are unexpected
-
Potential outliers that don’t make sense
-
Features that should be binary (i.e. “wannabe indicator variables”)
-
Boundaries that don’t make sense
-
Potential measurement errors
Plot Categorical Distributions
Categorical features cannot be visualized through histograms. Instead, you can use bar plots.
Study Correlations
Positive correlation means that as one feature increases, the other increases. E.g. a child’s age and her height.
Negative correlation means that as one feature increases, the other decreases. E.g. hours spent studying and number of parties attended.
Correlations near -1 or 1 indicate a strong relationship.
Those closer to 0 indicate a weak relationship.
0 indicates no relationship.
Data Cleaning
Better data beats fancier algorithms.
proper data cleaning can make or break your project. Professional data scientists usually spend a very large portion of their time on this step
Better data beats fancier algorithms.
commonly recommended ways of dealing with missing data
-
Missing categorical data The best way to handle missing data for categorical features is to simply label them as ’Missing’!
-
Missing numeric data
For missing numeric data, you should flag and fill the values.
Flag the observation with an indicator variable of missingness.
Then, fill the original missing value with 0 just to meet the technical requirement of no missing values.
Feature Engineering
creating new input features from your existing ones.
This is often one of the most valuable tasks a data scientist can do to improve model performance, for 3 big reasons:
- You can isolate and highlight key information, which helps your algorithms “focus” on what’s important.
- You can bring in your own domain expertise.
- Most importantly, once you understand the “vocabulary” of feature engineering, you can bring in other people’s domain expertise!
Sparse classes (in categorical features) are those that have very few total observations. They can be problematic for certain machine learning algorithms, causing models to be overfit.
Add Dummy Variables
Dummy variables are a set of binary (0 or 1) variables that each represent a single class from a categorical feature.
Unused features are those that don’t make sense to pass into our machine learning algorithms.
The key is choosing machine learning algorithms that can automatically select the best features among many options (built-in feature selection).
There are 3 common types of regularized linear regression algorithms:
-
Lasso Regression
-
Ridge Regression
-
Elastic-Net
How to Train ML Models
1-Split Dataset
Training sets are used to fit and tune your models. Test sets are put aside as “unseen” data to evaluate your models.
2-
There are two types of parameters in machine learning algorithms.
1-Model parameters
2- Hyperparameters
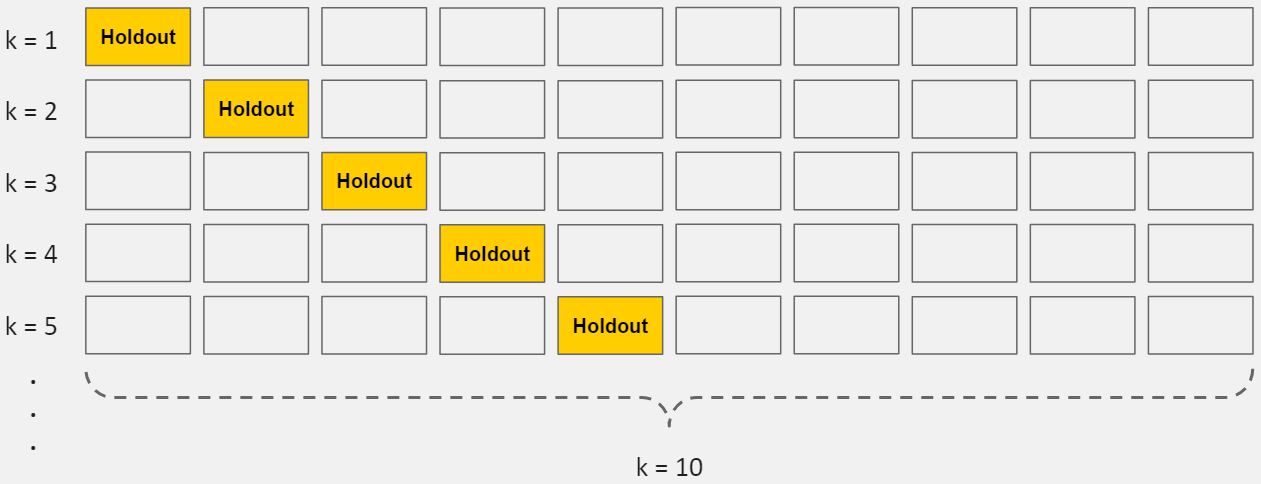
Cross-validation
is a method for getting a reliable estimate of model performance using only your training data.
Select Winning Model
- For regression tasks, we recommend Mean Squared Error (MSE) or Mean Absolute Error (MAE). (Lower values are better)
- For classification tasks, we recommend Area Under ROC Curve (AUROC). (Higher values are better)